
Applies to PeerGFS v6.1.0 and later
Overview
This article expands on the workflow and high-level tasks described in Creating a Job Using Scripting. It provides a detailed example of how to create a job using Bash and a job template. This example demonstrates how to use a job template to pass user options on to the newly created job.
Task 1: Configure NAS devices (if applicable)
Any NAS devices used for jobs need to be preconfigured in the Peer Management Center (PMC) user interface.
Step 1. Open the PMC, select Tools, and then select Open Preferences from the main menu.
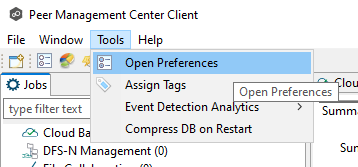
Step 2. In the NAS Configuration section, select a platform and configure the NAS devices.
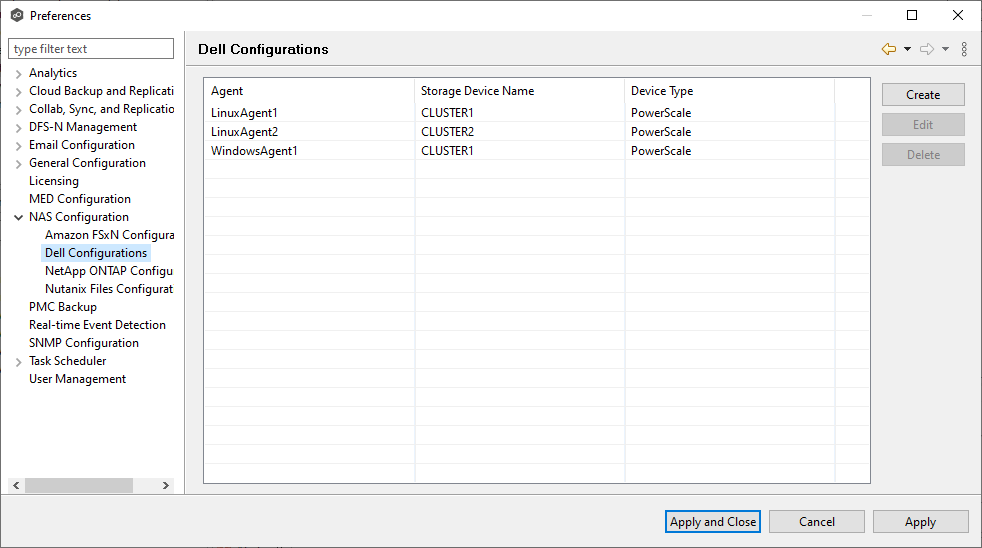
For more detailed guidance on setting up NAS devices, see the PeerGFS User Guide..
Task 2: Create a template job
Creating a template job is useful when using the API to create jobs regularly. The template allows you to set parameters that are not default or available through the API.
To create the template job, run the following API command in a Bash terminal:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" createJob jobName="TemplateJob" jobType=FILE_REPLICATION
The JobType parameter can be set to FILE_COLLABORATION, SYNCHRONIZATION_ONLY, or FILE_REPLICATION.

Once created, the job will appear in the user interface with a unique icon, indicating that it has no participants.
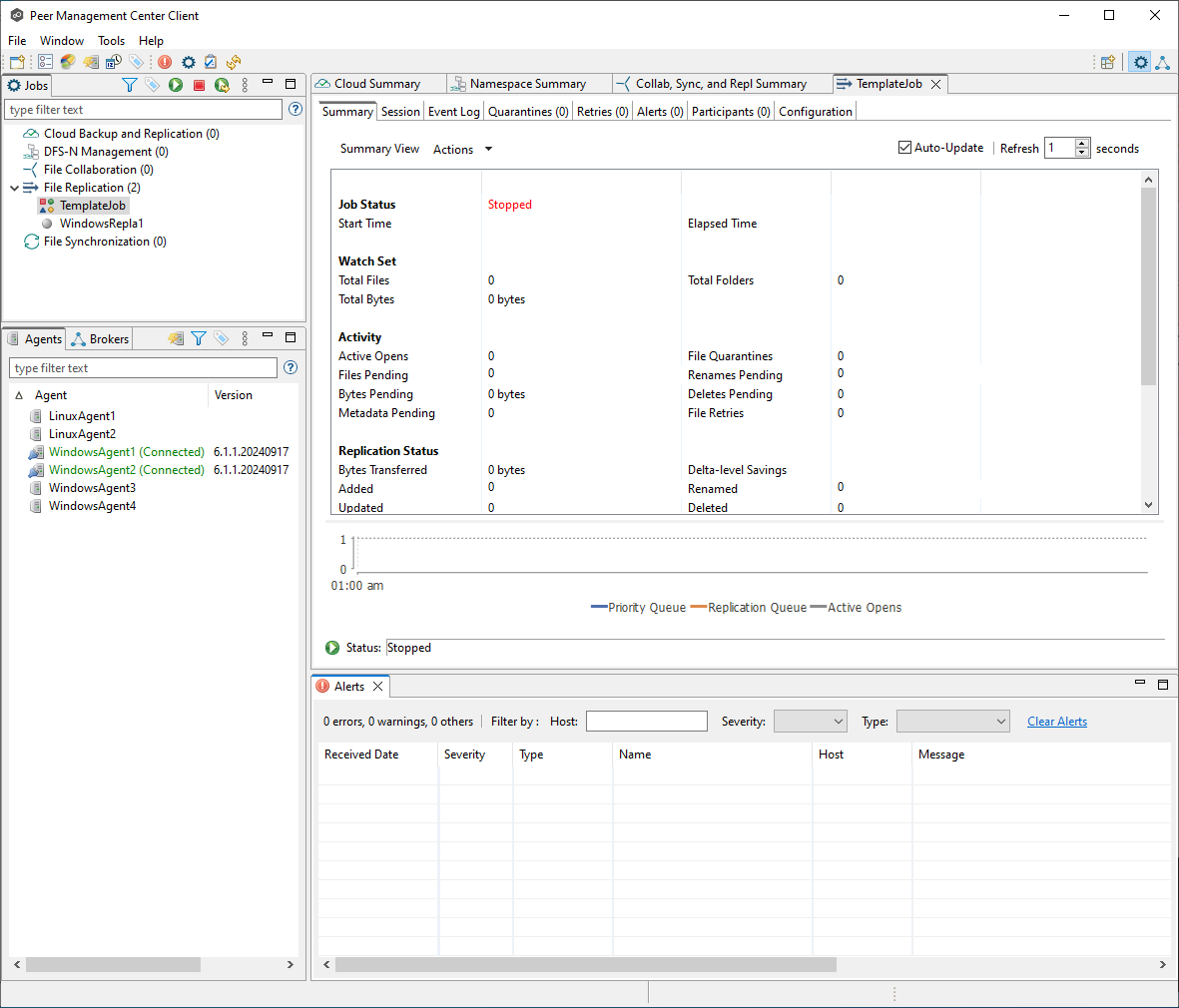
Task 3: Edit options to be passed on to new jobs
Step 1. Right-click the job and select Edit Job.
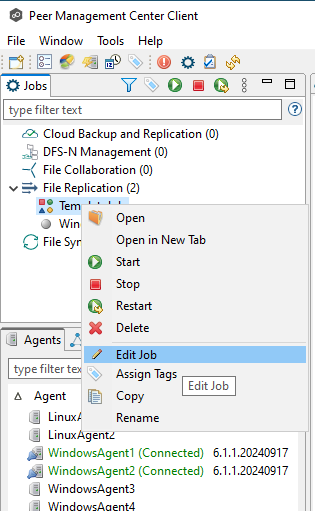
Step 2. Make the necessary changes to the job. In this example, we are adjusting the transfer size.
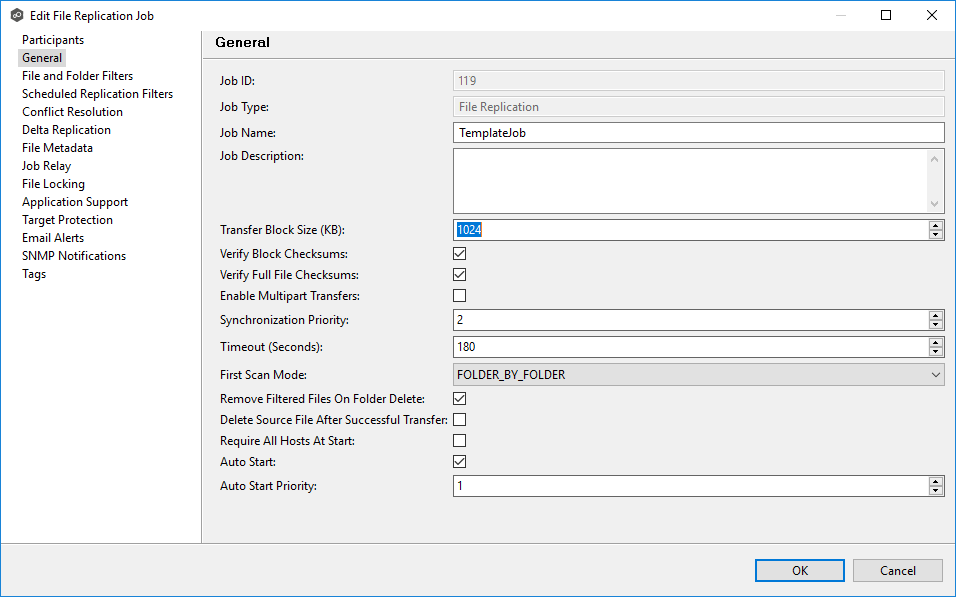
Step 3. Click OK to save the changes.
Task 4: Create the job
Once the previous tasks are complete, production jobs can be created via the API without further UI interaction. To create the production job, run the following command using PowerShell:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" createJob jobName=LinuxJob jobType=FILE_REPLICATION refJobId=106
Where RefJobId is the job ID of the template job.

If the returned job ID was not recorded, it can be retrieved by listing all jobs:
jobs=`./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" getJobs`
echo $jobs | python -m json.tool
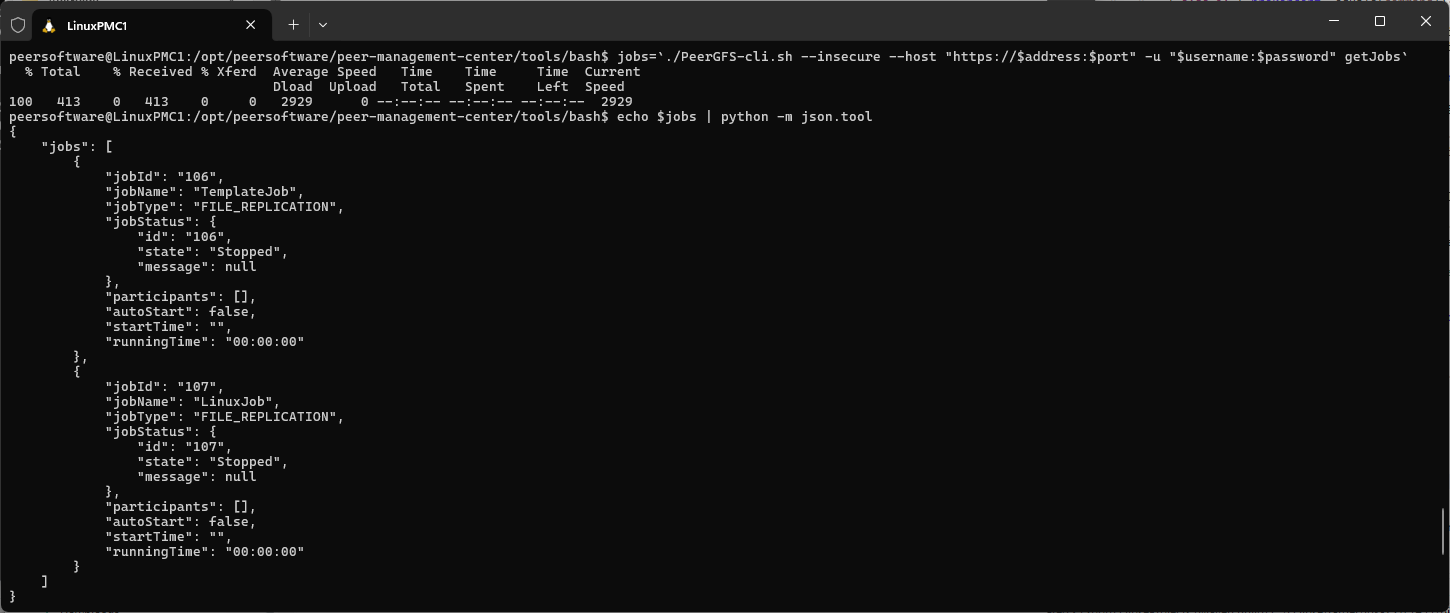
For scripting purposes, the job ID returned in the JSON-formatted response can be stored in a variable. For example:
export jobID=107
Task 5: Add participants to the job
Now that the job is created, participants need to be added. Participants are paths within storage volumes (either NAS or local to Agents) for data movement to occur.
Step 1. List available storage devices
Run the following command to list available storage devices:
storage=`./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" getStorage`
echo $storage | python -m json.tool
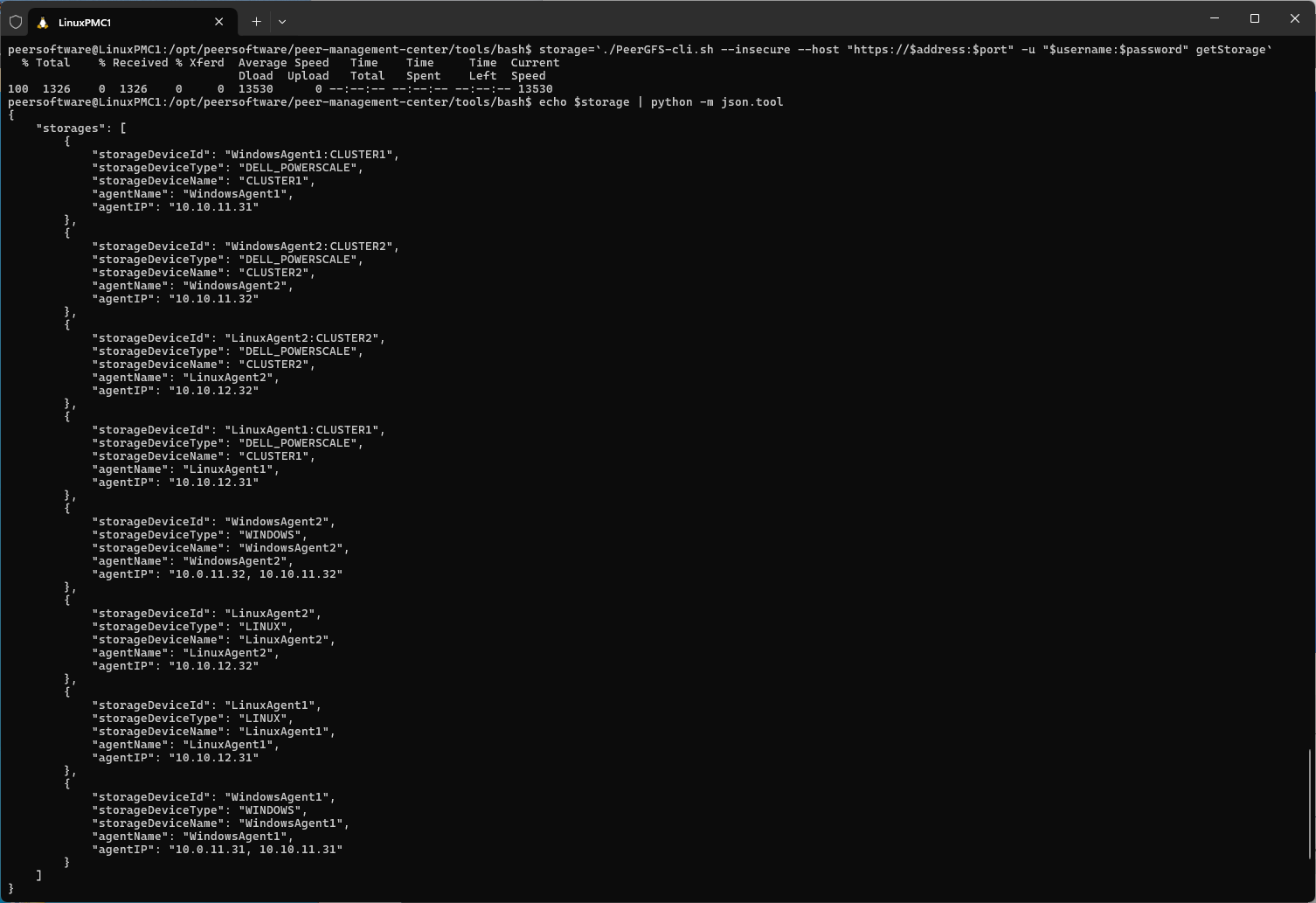
Storage volumes are returned as a JSON list, which can be processed logically or manually inspected. If volumes of a specific type are needed, the StorageDeviceType option can be used:
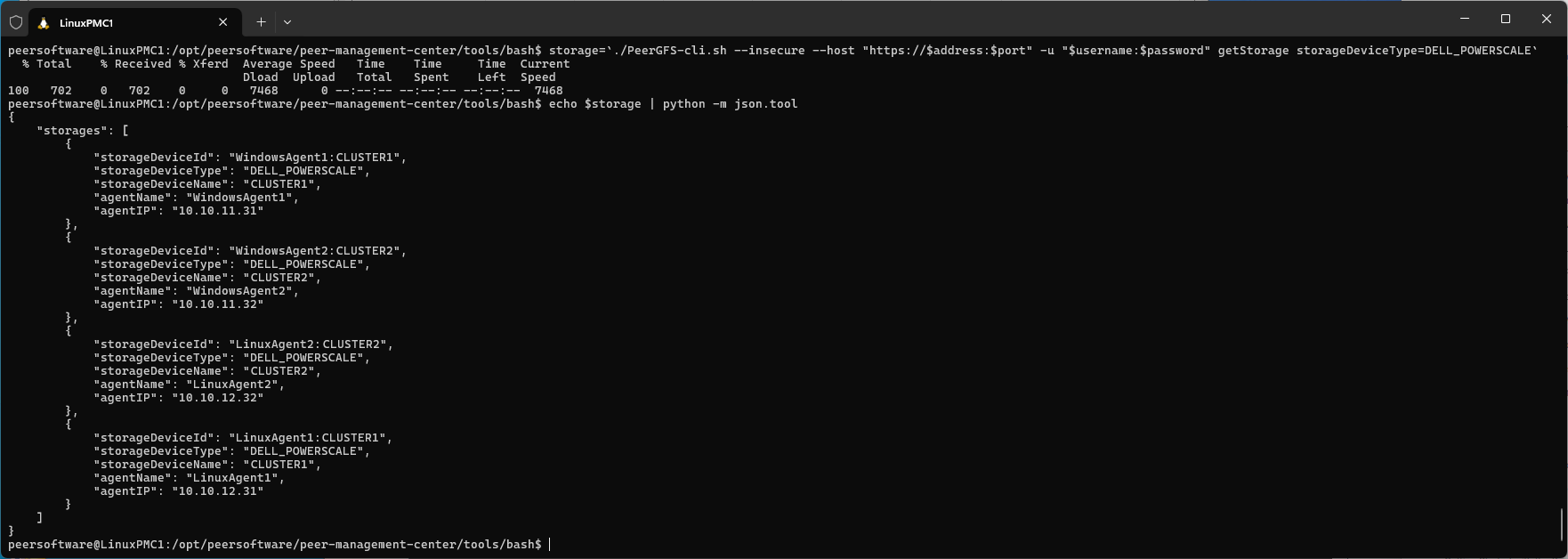
storage=`./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" getStorage storageDeviceType=DELL_POWERSCALE`
echo $storage | python -m json.tool
Example output (filtered for DELL_POWERSCALE):
Step 2. Add Participants
Each participant must be added in turn. For replication jobs, there will only be one source participant. The following command adds the source participant:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" addParticipant jobId=$jobID storageDeviceId=LinuxAgent1:CLUSTER1 path=CLUSTER1:/ifs/workspace

For all other participants, the -SeedingTarget $true option must be added:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" addParticipant jobId=$jobID storageDeviceId=LinuxAgent2:CLUSTER2 path=CLUSTER2:/ifs/workspace seedingTarget=true
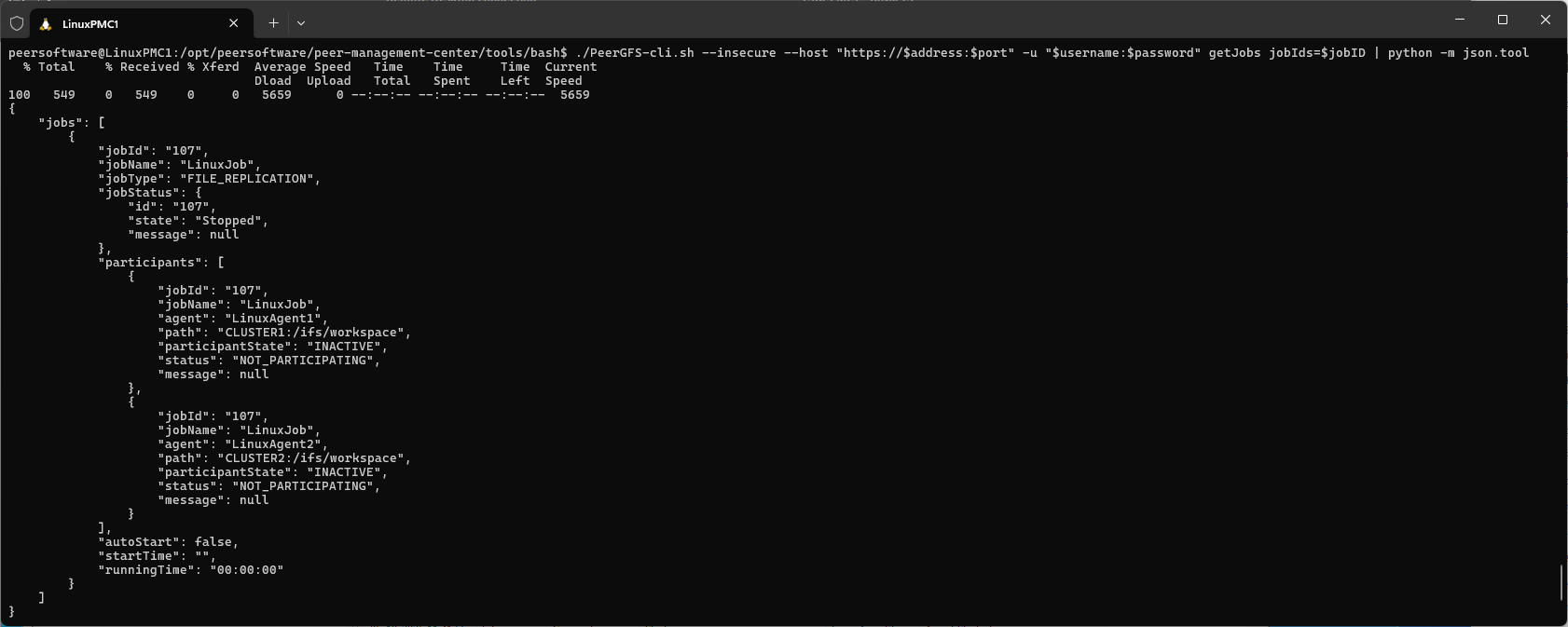
Once all participants have been added, you can retrieve and view the job details:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" getJobs jobIds=$jobID | python -m json.tool
Task 6: Start the job
Once the job has been fully configured, it needs to be started manually. To start the job, run the following command:
./PeerGFS-cli.sh --insecure --host "https://$address:$port" -u "$username:$password" startJob jobIds=$jobID

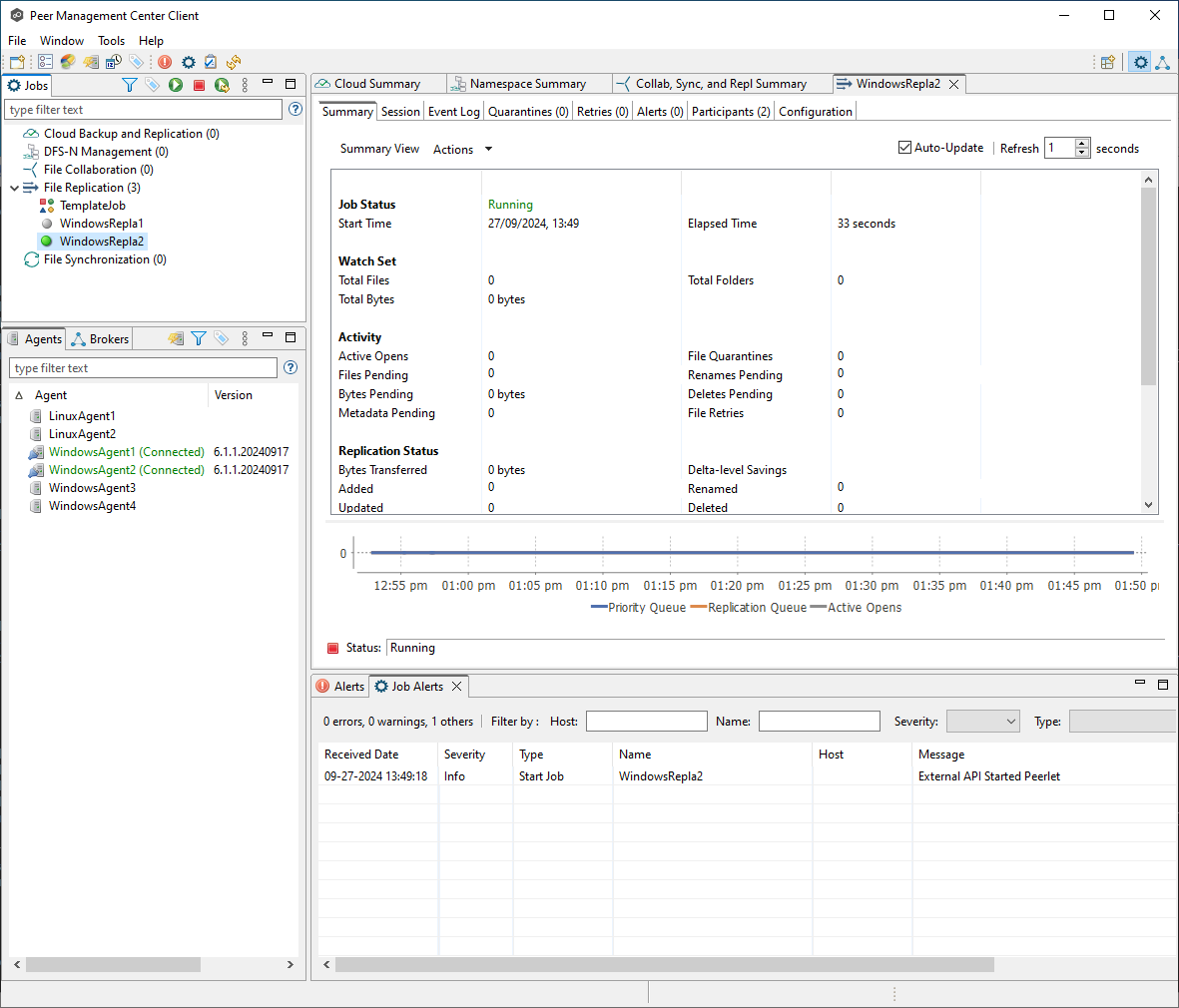
After executing the command, the job will be in a running state. You can confirm this by checking the UI, where the job will now appear as running.
Related articles
- Check .pc-trash_bin date stored times for target protection
- Creating a Job Using Bash Scripting
- Creating a Job Using PowerShell Scripting
- Creating a Job Using Scripting
- Does the EOA of NetApp ONTAPI impact PeerGFS?
- Generating Client Code for PeerGFS API with Swagger.io
- Getting Started with the PeerGFS REST API
- Performing API Operations Using Bash
- Performing API Operations Using cURL
- Performing API Operations Using PowerShell
- Scripting Methods for API Operations
- Use PowerShell to connect to the PeerGFS API